publications
2026
-
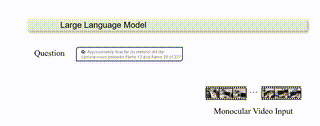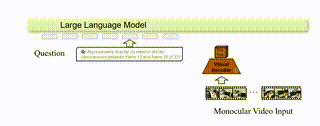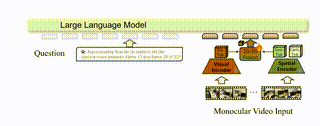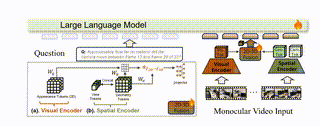 VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D ReconstructionZhiwen Fan*, Jian Zhang*, Renjie Li, and 8 more authorsIn CVPR, 2026
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D ReconstructionZhiwen Fan*, Jian Zhang*, Renjie Li, and 8 more authorsIn CVPR, 2026The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.

2025
-
 DynamicVerse: A Physically-Aware Multimodal Framework for 4D World ModelingKairun Wen, Runyu Chen, Hui Zheng, and 8 more authorsIn NeurIPS, 2025
DynamicVerse: A Physically-Aware Multimodal Framework for 4D World ModelingKairun Wen, Runyu Chen, Hui Zheng, and 8 more authorsIn NeurIPS, 2025Understanding the dynamic physical world, characterized by its evolving 3D structure, real-world motion, and semantic content with textual descriptions, is crucial for human-agent interaction and enables embodied agents to perceive and act within real environments with human-like capabilities. However, existing datasets are often derived from limited simulators or utilize traditional Structure-from-Motion for up-to-scale annotation and offer limited descriptive captioning, which restricts the capacity of foundation models to accurately interpret real-world dynamics from monocular videos, commonly sourced from the internet. To bridge these gaps, we introduce DynamicVerse, a physical-scale, multimodal 4D world modeling framework for dynamic real-world video. We employ large vision, geometric, and multimodal models to interpret metric-scale static geometry, real-world dynamic motion, instance-level masks, and holistic descriptive captions. By integrating window-based Bundle Adjustment with global optimization, our method converts long real-world video sequences into a comprehensive 4D multimodal format. DynamicVerse delivers a large-scale dataset consists of 100K+ videos with 800K+ annotated masks and 10M+ frames from internet videos. Experimental evaluations on three benchmark tasks, namely video depth estimation, camera pose estimation, and camera intrinsics estimation, demonstrate that our 4D modeling achieves superior performance in capturing physical-scale measurements with greater global accuracy than existing methods.
2024
-
 Large spatial model: End-to-end unposed images to semantic 3dZhiwen Fan*, Jian Zhang*, Wenyan Cong, and 8 more authorsIn NeurIPS, 2024
Large spatial model: End-to-end unposed images to semantic 3dZhiwen Fan*, Jian Zhang*, Wenyan Cong, and 8 more authorsIn NeurIPS, 2024Reconstructing and understanding 3D structures from a limited number of images is a well-established problem in computer vision. Traditional methods usually break this task into multiple subtasks, each requiring complex transformations between different data representations. For instance, dense reconstruction through Structure-from-Motion (SfM) involves converting images into key points, optimizing camera parameters, and estimating structures. Afterward, accurate sparse reconstructions are required for further dense modeling, which is subsequently fed into task-specific neural networks. This multi-step process results in considerable processing time and increased engineering complexity. In this work, we present the Large Spatial Model (LSM), which processes unposed RGB images directly into semantic radiance fields. LSM simultaneously estimates geometry, appearance, and semantics in a single feed-forward operation, and it can generate versatile label maps by interacting with language at novel viewpoints. Leveraging a Transformer-based architecture, LSM integrates global geometry through pixel-aligned point maps. To enhance spatial attribute regression, we incorporate local context aggregation with multi-scale fusion, improving the accuracy of fine local details. To tackle the scarcity of labeled 3D semantic data and enable natural language-driven scene manipulation, we incorporate a pre-trained 2D language-based segmentation model into a 3D-consistent semantic feature field. An efficient decoder then parameterizes a set of semantic anisotropic Gaussians, facilitating supervised end-to-end learning. Extensive experiments across various tasks show that LSM unifies multiple 3D vision tasks directly from unposed images, achieving real-time semantic 3D reconstruction for the first time.
-
 Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 secondsZhiwen Fan, Wenyan Cong, Kairun Wen, and 8 more authorsarXiv preprint, 2024
Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 secondsZhiwen Fan, Wenyan Cong, Kairun Wen, and 8 more authorsarXiv preprint, 2024While neural 3D reconstruction has advanced substantially, its performance significantly degrades with sparse-view data, which limits its broader applicability, since SfM is often unreliable in sparse-view scenarios where feature matches are scarce. In this paper, we introduce InstantSplat, a novel approach for addressing sparse-view 3D scene reconstruction at lightning-fast speed. InstantSplat employs a self-supervised framework that optimizes 3D scene representation and camera poses by unprojecting 2D pixels into 3D space and aligning them using differentiable neural rendering. The optimization process is initialized with a large-scale trained geometric foundation model, which provides dense priors that yield initial points through model inference, after which we further optimize all scene parameters using photometric errors. To mitigate redundancy introduced by the prior model, we propose a co-visibility-based geometry initialization, and a Gaussian-based bundle adjustment is employed to rapidly adapt both the scene representation and camera parameters without relying on a complex adaptive density control process. Overall, InstantSplat is compatible with multiple point-based representations for view synthesis and surface reconstruction. It achieves an acceleration of over 30x in reconstruction and improves visual quality (SSIM) from 0.3755 to 0.7624 compared to traditional SfM with 3D-GS.

